





Most AI tools are stuck in their own lane. Your text generator can’t interpret an image, and your image creator has no idea what your ad copy says. This forces you to manually connect the dots between different systems, leading to disjointed work that misses the bigger picture.
That’s why we put dozens of Multimodal AI tools to the test. We focused on finding platforms that actually understand text, images, and sound together.
Our rankings are based on real-world performance in marketing, design, and analysis, not just empty marketing promises.
How Multimodal AI Tools Process Text, Images, and Audio Simultaneously?
The secret lies in encoders and fusion mechanisms that translate diverse inputs into a shared numerical language. Specialized components break down each data type—image encoders analyze colors, shapes, and objects, text encoders transform words into meaning-rich vectors, and audio encoders decode sound patterns into machine-readable values.
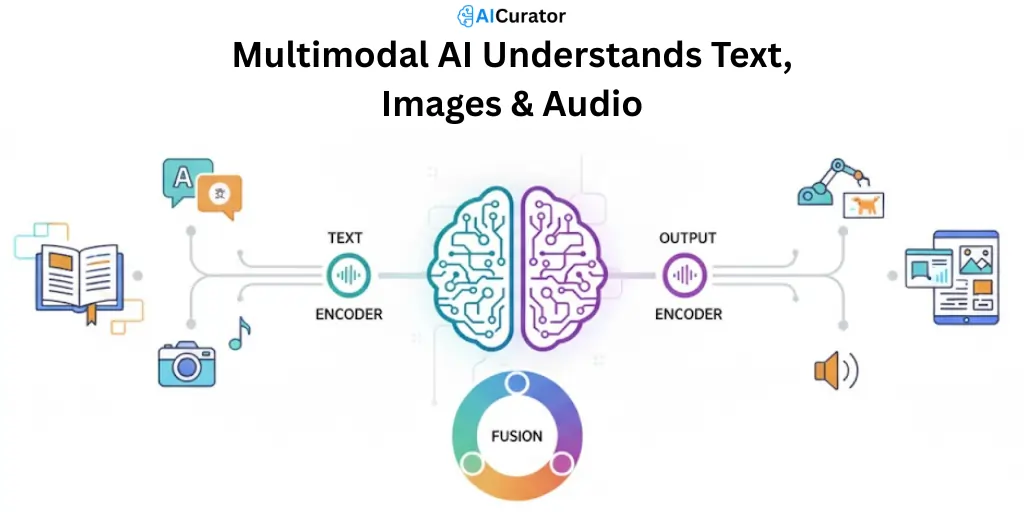
Once converted, a fusion mechanism connects the dots between these different formats. The system learns to link “dog” in text with a visual of a canine and the sound of barking, creating a unified understanding that goes beyond what single-format AI can achieve.
This cross-modal integration enables multimodal AI tools to deliver outputs that are contextually sharper and more accurate, making them ideal for complex tasks where one data type alone won't cut it.
Leading Multimodal AI Tools Every Creator and Developer Should Know
| 🤖 Top Multimodal AI Tools | 🎯 Best For | ⭐ Key Strength |
|---|---|---|
| Google Gemini | Enterprise-level reasoning | Native video processing |
| OpenAI GPT-4o | Real-time conversations | 232ms audio response |
| Anthropic Claude 3.5 Sonnet | Document analysis & vision | Large context window + improved image understanding |
| Meta Llama 4 Vision | Developer-first multimodal | Advanced image/text reasoning, open-source, scalable |
| Runway Gen-3 | Video content creation | Enhanced text-to-video quality |
| xAI Grok | Real-time social insights | X platform integration |
1. Google Gemini
Google Gemini breaks away from single-format AI by handling text, code, images, audio, and video natively—all within one system. Built by DeepMind, it's engineered to move fluidly between data types, making it a go-to for developers tackling cross-modal projects.
What sets it apart is the depth of its reasoning engine. Gemini doesn't just recognize different inputs—it connects them, pulling context from one format to enhance understanding of another. That means faster, sharper outputs for tasks where complexity spans multiple media types.
Google Gemini Key Features
Why Choose Gemini?
For projects that demand a flexible and powerful foundation, choose Google Gemini to handle diverse data inputs with exceptional skill.
2. OpenAI GPT-4o
OpenAI's GPT-4o (“o” for omni) is engineered for more natural human-computer interaction. It accepts any combination of text, audio, and image as input and generates responses in text, audio, and image formats, all with remarkable speed.
This AI multimodal brings a new level of interactivity to AI. Its ability to respond to audio in near real-time and perceive emotion makes conversations feel incredibly fluid and engaging, setting a new standard for digital assistants.
OpenAI GPT-4o Key Features
Why Choose GPT-4o?
Choose GPT-4o for its unmatched speed and efficiency in creating real-time, human-like AI conversations across various media formats.
3. Anthropic Claude 3.5 Sonnet
Anthropic's Claude 3.5 Sonnet is the latest iteration in the Claude family, offering a significant leap in vision capabilities and reasoning. It balances intelligence with speed, making it ideal for developers and enterprises processing complex documents, images, and multi-format data simultaneously.
With enhanced visual understanding and a massive context window, Claude 3.5 Sonnet excels at analyzing lengthy documents, technical diagrams, and intricate visual information. Its reasoning depth makes it particularly useful for tasks requiring nuanced interpretation across multiple data types.
Anthropic Claude 3.5 Sonnet Key Features
Why Choose Claude 3.5 Sonnet?
Choose Claude 3.5 Sonnet for document-heavy workflows and visual analysis demanding precision, speed, and deep contextual understanding.
4. Meta Llama 4 Vision

Meta’s Llama 4 Vision sets the new standard for open-source multimodal AI, offering superior image and language integration for enterprise and developer use. It can process and reason across text and images with heightened accuracy, efficient resource use, and scalable deployment options.
Meta Llama 4 Vision Key Features
Why Choose Llama 4 Vision?
Select Llama 4 Vision for flexible, privacy-focused, and advanced multimodal AI tailored for developer control and enterprise reliability.
5. Runway Gen-3
Runway Gen-3 is the latest evolution in AI-powered video generation, enabling creators to produce high-quality videos from text prompts, images, or video clips. It represents a significant step forward in text-to-video technology with improved coherence and visual quality.
This platform combines intuitive controls with advanced AI capabilities, letting creators direct the style, pacing, and content of generated videos. With enhanced motion synthesis and better prompt understanding, Gen-3 transforms creative concepts into polished video content faster than ever.
Runway Gen-3 Key Features
Why Choose Gen-3?
For video creators seeking cutting-edge quality and control, choose Runway Gen-3 to produce professional-grade video content with ease.
6. xAI Grok
Grok is an AI developed by xAI, designed to be more than just an information source. It has a rebellious and witty personality, aiming to answer questions with a bit of humour, which sets it apart from other AI models.
A key feature of Grok is its real-time knowledge of the world, sourced directly through the X (formerly Twitter) platform. This gives it a unique advantage in answering topical questions and providing up-to-the-minute insights.
xAI Grok Key Features
Why Choose Grok?
For answers with personality and real-time social knowledge, choose Grok to tap directly into the current pulse of X.
Multimodal AI Tools vs. Traditional AI: Understanding the Performance Gap
Traditional AI stumbles where multimodal systems thrive—contextual understanding. Unimodal models process text, images, or audio in isolation, missing the cross-modal patterns that define real-world scenarios.
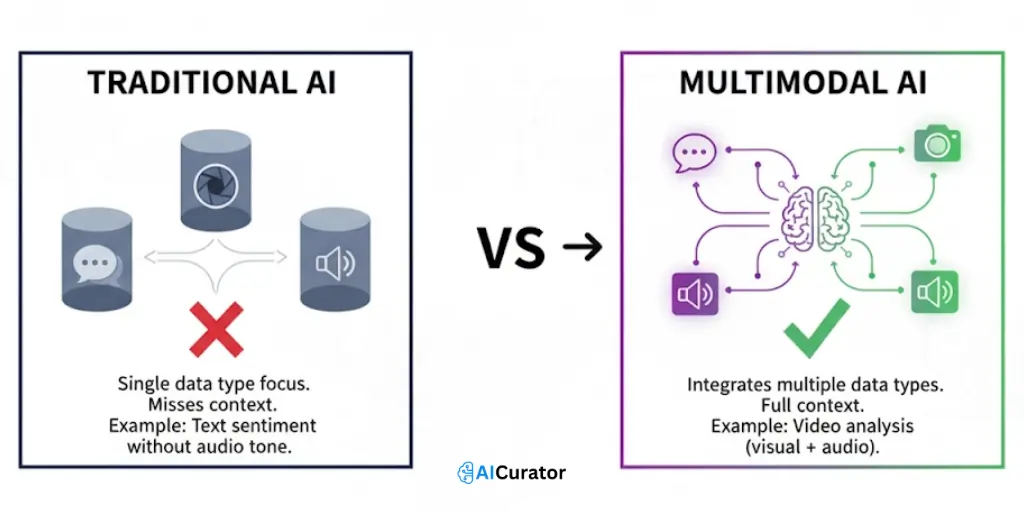
A sentiment analyzer reads words but ignores sarcastic vocal tone; an image classifier sees objects but can't connect them to spoken context.
Multimodal AI fuses these data streams simultaneously, identifying relationships single-format systems can't detect.
It generates images from voice commands, describes visuals with text, and spots video events using audio-visual cues together. The result: 40-60% accuracy gains in complex tasks.
Gaining Your Competitive Edge with Multimodal AI
Processing text, images, and audio in one system isn't a luxury anymore—it's how brands cut content production time by 70% and spot patterns competitors miss. Marketers using these platforms report faster campaign turnarounds, sharper targeting, and ad creatives that actually convert.
The gap between businesses leveraging cross-modal AI and those stuck with single-format systems widens daily. Your move: test one platform against your current workflow and measure the output difference yourself.
Recommended Readings:









{kind=link}