





Messy spreadsheets and scattered files can derail any data analysis workflow.
Lilac brings structure to your machine learning pipeline—transform raw data, filter for relevance, and export actionable insights with ease.
Built-in clustering, semantic search, and duplicate detection streamline every stage, making it simple for data scientists and ML engineers to manage complex datasets.
With Lilac, building a reliable data analysis workflow means faster results and more accurate analytics, all in one platform.
Why Lilac? The Modern Data Analysis Powerhouse
Traditional data tools force you to juggle multiple platforms and complex scripts. Lilac changes that by consolidating data curation, enrichment, and transformation into a single, developer-friendly toolkit.
Built specifically for modern machine learning workflows, it handles everything from LLM fine-tuning preparation to AI agent development. The combination of Python API flexibility and intuitive UI makes data analysis workflow management straightforward, turning chaotic datasets into clean, structured outputs ready for immediate use.
Unique Perks of Lilac
Step 1: Setting Up Lilac in Your Python Environment
Before jumping into data wrangling, let’s get Lilac installed and ready to roll.
# Install Lilac with all optional dependencies
pip install lilac[all]Set your project directory for smooth file management:
import lilac as ll
ll.set_project_dir('~/my_project')This ensures all your data, configs, and outputs are neatly organised—a must for reproducible workflows.
Step 2: Loading and Creating Your Dataset
Lilac makes it easy to pull in data from popular sources like HuggingFace. For this guide, we’ll use an instruction dataset, but you can adapt these steps for your own CSVs, JSONs, or API feeds.
source = ll.HuggingFaceSource(dataset_name='Open-Orca/OpenOrca', sample_size=10_000)
config = ll.DatasetConfig(namespace='local', name='open-orca-10k', source=source)
dataset = ll.create_dataset(config)💡 Pro tip: Lilac can scale to millions of rows, but starting with a smaller sample (like 10,000) is great for prototyping.
Step 3: Transforming Data with Lilac’s Python API
Data rarely comes clean. Lilac’s map primitive lets you run custom Python functions across your dataset for transformation and enrichment.
Example: Standardising Text Fields
Suppose you want to lowercase all instruction texts for consistency:
def to_lower(row):
row['instruction'] = row['instruction'].lower()
return row
dataset = dataset.map(to_lower)You can chain multiple transformations—think removing stopwords, normalising dates, or extracting entities—all within Lilac’s efficient pipeline.
Step 4: Filtering Data for Quality and Relevance

Quality data is the backbone of any successful analysis or ML project. Lilac offers several built-in signals and filters:
Example: Filtering Out Short Instructions
def long_enough(row):
return len(row['instruction'].split()) > 5
filtered_dataset = dataset.filter(long_enough)Built-in Signal Computation
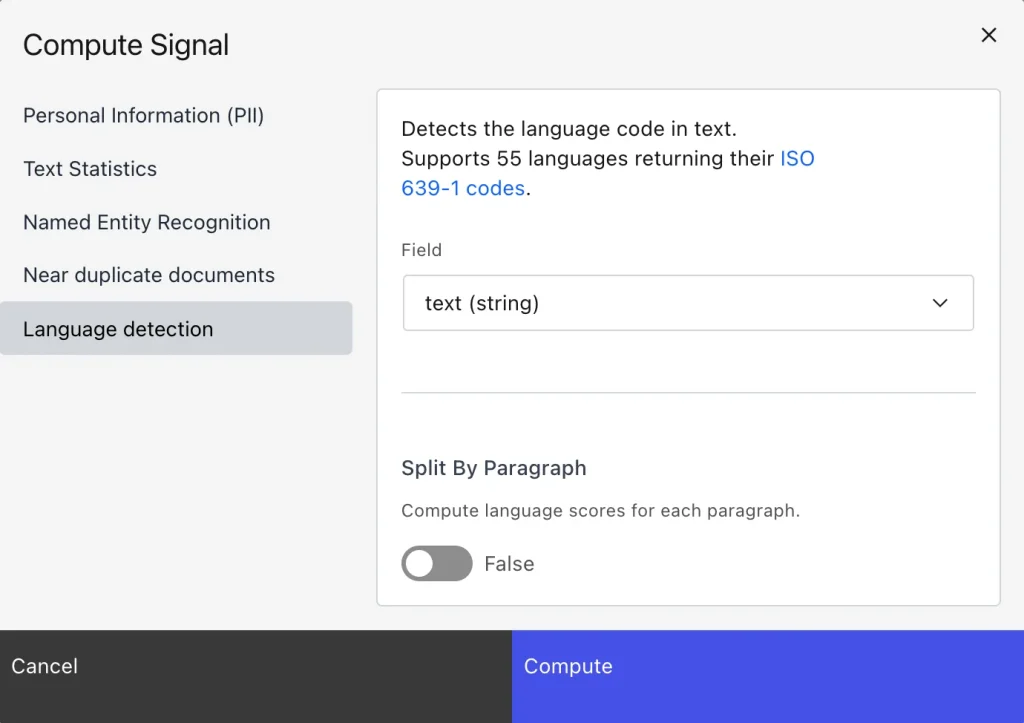
Lilac’s UI and API let you compute signals like PII or near-duplicates:
To compute a signal from the UI, expand the schema in the top left corner, and select ‘Compute Signal’ from the context menu of the field you want to enrich.
This step is essential for cleaning up noisy data and ensuring your insights are robust.
Step 5: Enriching the Dataset with Concepts and Labels
For advanced workflows—like prepping data for LLM fine-tuning or AI agent training—enrichment is key.
Example: Adding a “Topic” Label
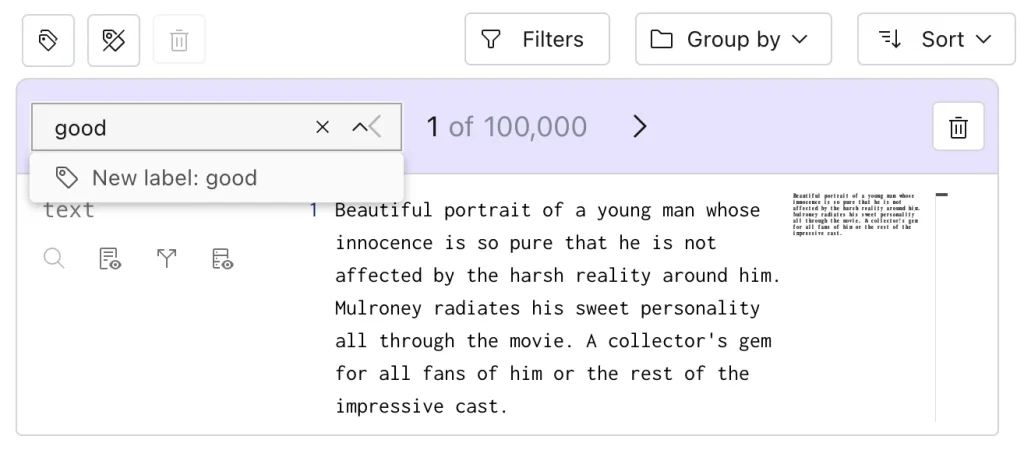
You could use a simple keyword-based function or an NLP model to assign topics:
def add_topic(row):
if 'summarise' in row['instruction']:
row['topic'] = 'summarisation'
else:
row['topic'] = 'other'
return row
enriched_dataset = filtered_dataset.map(add_topic)Step 6: Exporting Structured Insights
Once your dataset is transformed, filtered, and enriched, Lilac makes exporting a breeze.
Export via Python
enriched_dataset.to_json('enriched_data.json')Export via Lilac UI
For larger datasets or more control, the Python API is recommended. For quick exports, use the UI’s browser download feature.
We recommend the python API for downloading large amounts of data, or if you need a better control over the selection of data.
Step 7: Using Your Data—From Analytics to AI
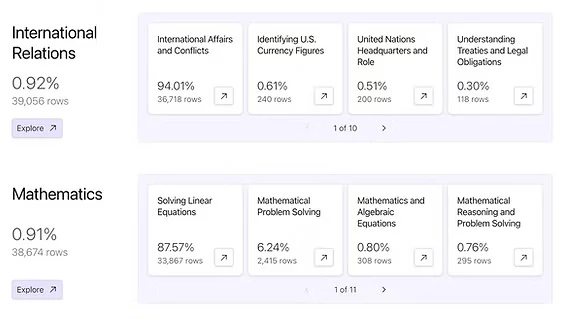
Your exported, structured dataset is now ready for:
Lilac’s flexible output formats (JSON, CSV, etc.) make integration with downstream tools seamless, whether you’re building dashboards, training models, or sharing insights with your team.
Tips from the AI Community: Best Practices for Lilac Workflows
Conclusion
Building a functional data analysis workflow with Lilac empowers you to change, filter, and export structured insights with minimal fuss and maximum scalability. Whether you’re a data scientist, AI developer, or digital marketer, Lilac’s powerful API and UI features make it a top choice for prepping datasets for analytics, LLM fine-tuning, and AI agent training.
By following this guide and tapping into community best practices, you’ll streamline your workflow, boost productivity, and unlock richer insights from your data.
Ready to supercharge your next AI or data science project? Give Lilac a spin and experience the future of data curation firsthand.









{kind=link}