




RAG (Retrieval-Augmented Generation) combines real-time data retrieval with large language models, giving AI systems on-demand access to current facts. By 2026 this approach drives complex workflow automation and RAG for Multi-Tool Integration, coordinating CRMs, knowledge bases, and analytics platforms from a single interface.
Organisations now treat RAG as the default bridge to their internal data, replacing one-off fine-tunes and static models with dynamic retrieval pipelines.
Traditional LLMs pull answers from a fixed training snapshot; RAG extends that snapshot with live context, reducing hallucinations and grounding each response in verifiable sources.
How RAG Works: Core Components and Architecture
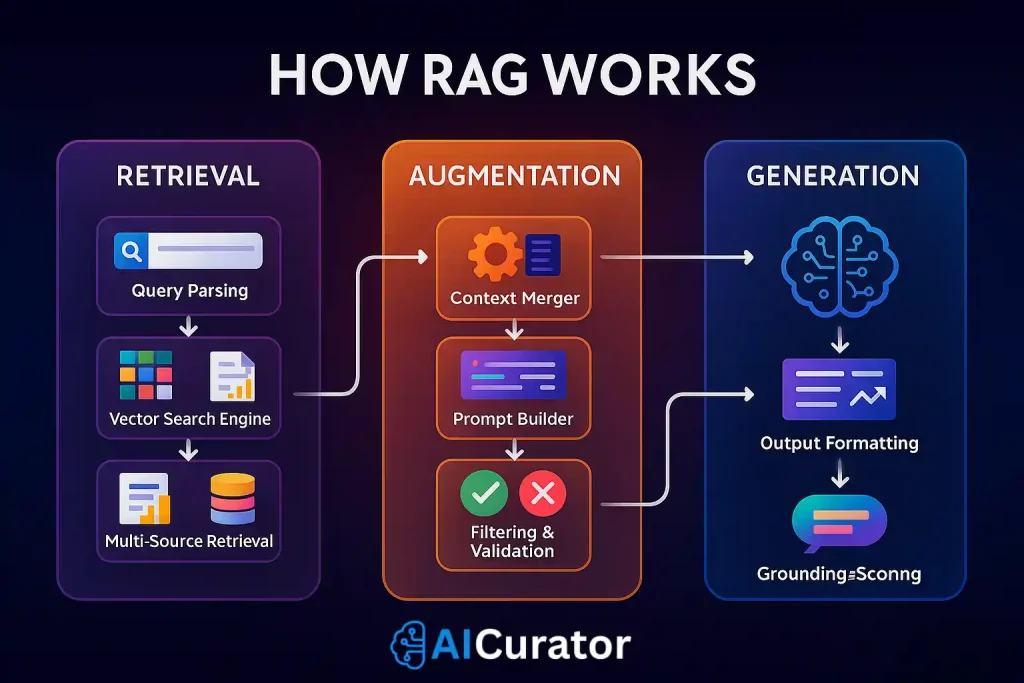
The RAG Pipeline Fundamentals
Retrieval-augmented generation workflow operates through three primary stages that work together to create intelligent responses:
1. Retrieval Phase
2. Augmentation Phase
3. Generation Phase
Key Technical Components
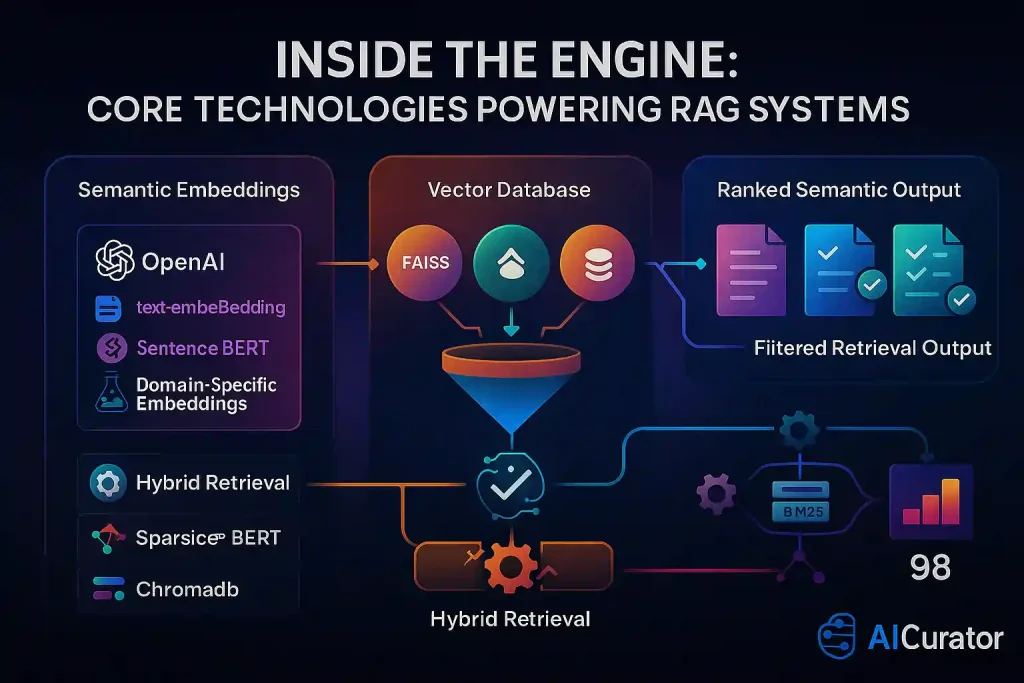
🛢️ Vector Databases and Embeddings
Modern RAG systems rely on sophisticated vector databases like FAISS, Chroma, or Pinecone to store and retrieve semantic information efficiently. These databases convert text into high-dimensional vectors using embedding models such as:
🔀 Retrieval Mechanisms
Advanced RAG implementations use hybrid retrieval strategies combining:
RAG for Multi-Tool Integration: Real-World Use Cases
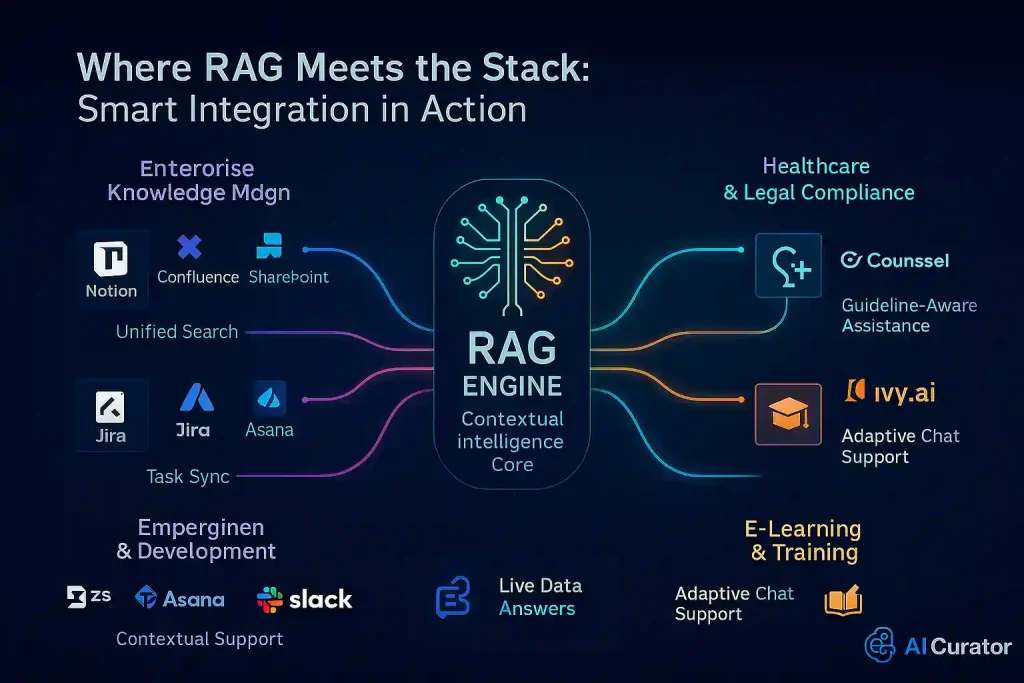
💼 Enterprise Knowledge Management
RAG AI tool orchestration excels at unifying disparate information sources within organisations. Companies like Grammarly and Okta use RAG-powered systems to create contextual search experiences across multiple applications.
Key Implementation Areas:
⚕️ Healthcare and Regulatory Compliance
In healthcare, RAG systems combine clinical guidelines with patient data to assist healthcare providers with treatment recommendations. Legal firms use RAG to reference case law and statutes, ensuring responses align with authoritative domain knowledge.
Thomson Reuters' CoCounsel exemplifies this approach, helping legal teams quickly retrieve relevant compliance data from massive legal databases.
🔬 Research and Development
RAG-powered research assistants connect to live data sources like academic databases and real-time information streams. Consensus, a RAG-based search engine, helps researchers extract answers and citations from scientific literature in real-time.
🎓 E-Learning and Training
Educational platforms use RAG to create adaptive learning experiences by connecting LLMs to course materials and lecture content. Ivy.ai integrates RAG with university course materials to power AI chatbots offering 24/7 student support.
Key Benefits of RAG-Based Smart Systems
✅ Enhanced Accuracy and Reduced Hallucinations
RAG systems dramatically reduce AI hallucinations by anchoring responses to specific retrieved content rather than relying on statistical patterns from training data. This approach creates more factually accurate outputs with clear provenance.
✅ Scalability and Performance
Real-time RAG implementation enables organisations to:
✅ Cost Efficiency
By avoiding frequent model retraining, RAG systems provide significant cost advantages:
✅ Personalised User Experiences
RAG enables AI systems to access information beyond training data, including proprietary documents and real-time information sources. This capability keeps responses current and relevant to specific user contexts.
Technical Architecture: Building RAG Systems
Multi-Modal RAG Architecture
Advanced RAG systems now support multiple data types through sophisticated architectures:
class MultiModalRAG:
def __init__(self):
self.text_embeddings = HuggingFaceEmbeddings()
self.image_embeddings = CLIPEmbeddings()
self.text_store = None
self.image_store = None
def process_multimodal_documents(self, documents):
for doc in documents:
# Extract text content
text_chunks = self.extract_text(doc)
text_embeddings = self.text_embeddings.embed_documents(text_chunks)
# Extract and process images
images = self.extract_images(doc)
image_embeddings = self.image_embeddings.embed_images(images)
# Store in respective vector stores
self.text_store.add_embeddings(text_chunks, text_embeddings)
self.image_store.add_embeddings(images, image_embeddings)Agentic RAG with Tool Integration
Intelligent agent systems transform passive retrieval into active reasoning by delegating sub-tasks to various tools and APIs. This approach enables complex workflows like:
Code Example: LangChain RAG Pipeline
Here's a comprehensive example of building a RAG pipeline using LangChain with OpenAI and FAISS:
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Document Loading and Processing
loader = TextLoader("enterprise_docs.txt")
documents = loader.load()
# 2. Text Splitting for Optimal Retrieval
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_documents(documents)
# 3. Embedding Generation and Vector Store Creation
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(chunks, embeddings)
# 4. Retriever Configuration
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
# 5. RAG Chain Assembly
llm = OpenAI(model="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True,
chain_type="stuff"
)
# 6. Query Processing
query = "How does our API integration work?"
result = qa_chain(query)
print(f"Answer: {result['result']}")Advanced RAG with API Connectors
For multi-tool integration, extend the basic pipeline with API connectors:
from langchain.tools import Tool
from langchain.agents import initialize_agent, AgentType
# Define tools for different platforms
def search_crm(query):
# CRM API integration logic
return crm_results
def search_notion(query):
# Notion API integration logic
return notion_results
tools = [
Tool(
name="CRM Search",
func=search_crm,
description="Search customer data in CRM system"
),
Tool(
name="Notion Search",
func=search_notion,
description="Search documentation in Notion"
)
]
# Create agent with multiple tools
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)RAG for Multi-Tool Integration: FAQ & Troubleshooting
How do I fix irrelevant document retrieval in a RAG workflow?
Check embedding quality, raise top-K value, and add a reranker to boost semantic match; this usually lifts retrieval precision by 10–15 percent.
Why does my RAG system still hallucinate answers?
Hallucinations often stem from missing or low-ranked sources; tighten filter thresholds and include source-grounding prompts to cut false facts by up to 40 percent.
What causes slow response times in RAG pipelines?
Latency spikes come from large vector stores or API bottlenecks; batch embeddings, cache frequent queries, and use GPU-accelerated DBs to shrink response time below 500 ms.
Can RAG work with multilingual queries?
Yes—train bilingual embeddings or use cross-lingual models; retrieval accuracy remains within 5 percent of monolingual baselines across 50+ languages.
Conclusion & Next Steps
RAG for Multi-Tool Integration now sits at the center of workflow automation, bridging live data and large language models in a single, verifiable loop.
From there, scale to full-stack orchestration across your organization.









{kind=link}