





Machine Learning Algorithms now process over 2.5 quintillion bytes of data daily, with companies reporting 23% faster deployment cycles when teams master core methodologies.
Big data offers little value until raw signals become reliable forecasts. Machine Learning Algorithms—rooted in supervised learning, ensemble methods, feature engineering, and dimensionality reduction—supply that conversion layer, turning terabytes into profit-driving insight.
Engineers who understand each model’s mathematical backbone, optimisation tricks, and generalisation pitfalls gain a decisive edge in predictive modeling, anomaly detection, and real-time analytics.
Accelerate your data science journey: the ten techniques below represent the quickest path from prototype to production accuracy, closing the gap between information overload and actionable results.
Implementing ML Algorithms – Essential Tips
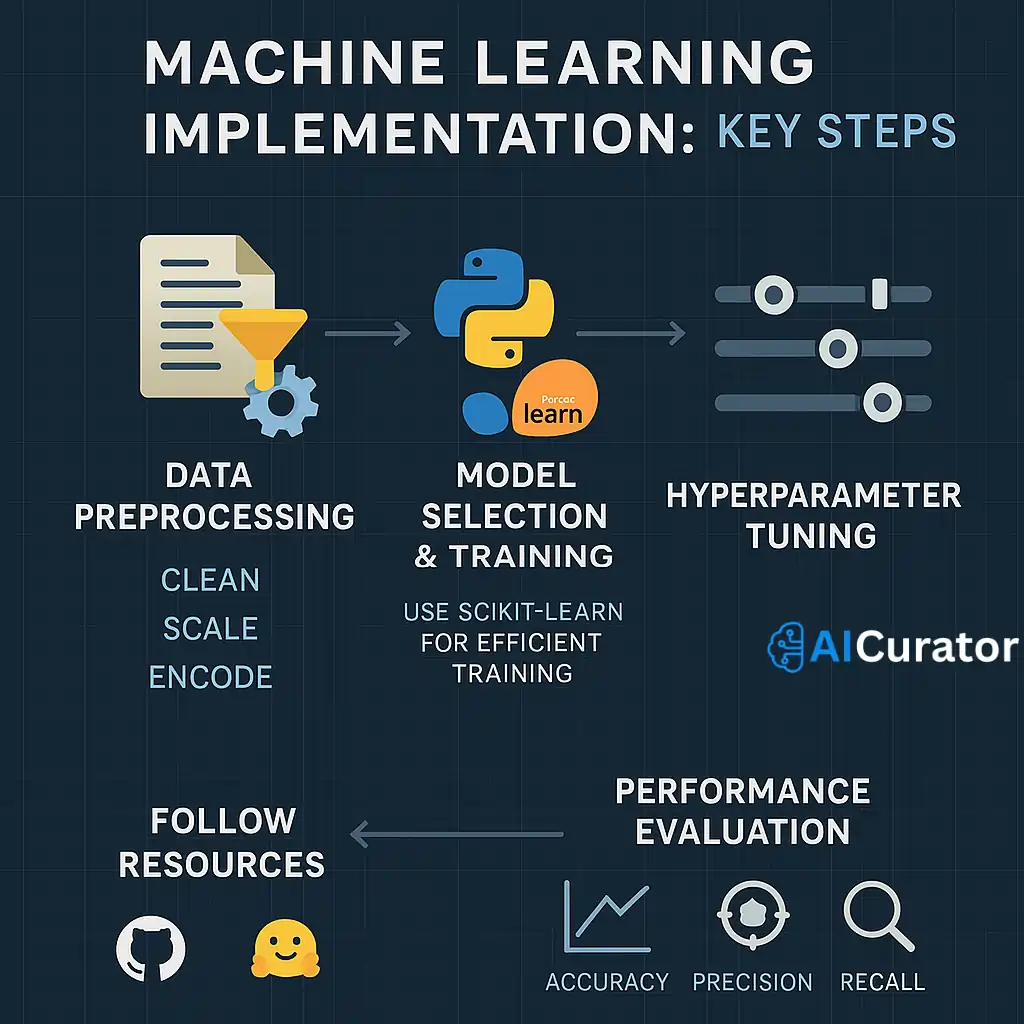
Master machine learning algorithms by focusing on data preprocessing, hyperparameter tuning, and cross-validation. Use Python libraries like scikit-learn for efficient model training.
Monitor metrics such as accuracy, precision, and recall to optimize performance across supervised and unsupervised ML models. Stay updated with GitHub repos and Hugging Face for practical implementations.
📊 Machine Learning Algorithms Comparison: Selection Guide
| Algorithm Category | Algorithm Type | Best Use Case | Primary Limitation |
|---|---|---|---|
| Linear Regression | Regression Algorithm | Continuous predictions | Linear assumptions |
| Logistic Regression | Classification Algorithm | Binary classification | Linear boundaries |
| Decision Tree | Supervised Learning | Rule-based decisions | Overfitting risk |
| SVM | Classification Algorithm | Complex boundaries | Computational cost |
| Naive Bayes | Probabilistic Algorithm | Text classification | Independence assumption |
| Neural Networks | Deep Learning Algorithm | Non-linear relationships | Data requirements |
| Self-Organizing Maps | Unsupervised Algorithm | Data visualization | Fixed structure |
| PCA | Dimensionality Reduction | High dimensions | Information loss |
| XGBoost | Ensemble Method | Structured data | Parameter complexity |
| LightGBM | Ensemble Algorithm | Large datasets | Overfitting potential |
1. Linear Regression: Foundation of Predictive Modeling

Among foundational Machine Learning Algorithms, Linear Regression finds the best-fit straight line to predict a numeric outcome from one or more inputs. It calculates coefficients showing how the output changes as each feature moves, helping explain relationships quickly.
Training is fast, works well when patterns stay roughly linear, and the results are easy to visualize. Its clarity makes it a frequent first pick for forecasting sales, prices, and other continuous values.
Key Parameters
python
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True, normalize=True)Applications: Real estate price prediction, sales forecasting, financial modeling
Pros
Cons
2. Logistic Regression: Essential Classification Algorithm
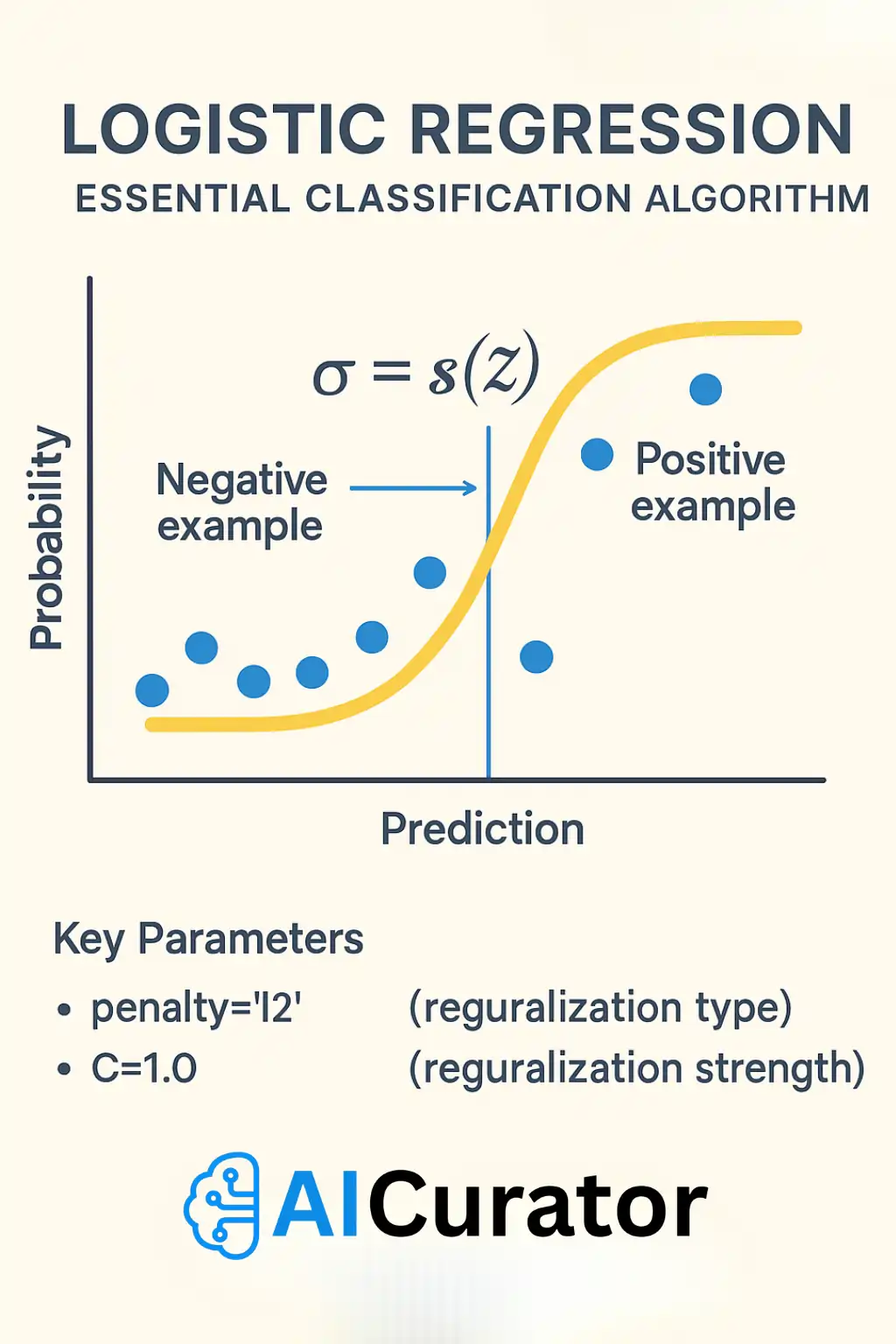
Logistic Regression handles yes-no style predictions by passing a weighted sum of inputs through a sigmoid curve that outputs probabilities from 0 to 1. You set a cutoff to label the result. The model is quick to train, interpretable through odds ratios, and easily extended with regularization to limit overfitting.
Because it needs limited computing power, it remains popular for email spam filters, credit approval checks, and many other everyday classification tasks.
Key Parameters
python
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2', C=1.0)Applications: Email spam detection, medical diagnosis, customer churn prediction
Pros
Cons
3. Decision Tree: Interpretable ML Algorithm
A Decision Tree breaks questions into a flow-chart of simple if-then splits, carving the data into groups that share similar outcomes. This ML algorithm captures non-linear patterns without heavy math or feature scaling, so it feels intuitive even to new practitioners.
Visualizing the branches reveals how each choice leads to a final prediction. Deep trees can memorize the training set, so pruning or combining many trees in ensembles helps keep results reliable.
Key Parameters
python
from sklearn.tree import DecisionTreeClassifie
model = DecisionTreeClassifier(max_depth=5, min_samples_split=2)Applications: Customer segmentation, loan approval systems, medical diagnosis
Pros
Cons
4. Support Vector Machine: Robust Classification Algorithm

SVM finds the line or surface that leaves the widest margin between classes, then relies on a handful of close points, called support vectors, to define that boundary. With kernel tricks, it handles curved splits without adding extra features by hand.
SVM shines on medium-sized, high-dimensional problems such as text categorization, though training time and parameter tuning grow with data size. Scaling and careful choice of kernel are key to good performance.
Key Parameters
python
from sklearn.svm import SVC
model = SVC(kernel='rbf', C=1.0)Applications: Image classification, text categorization, bioinformatics
Pros
Cons
5. Naive Bayes: Probabilistic ML Algorithm
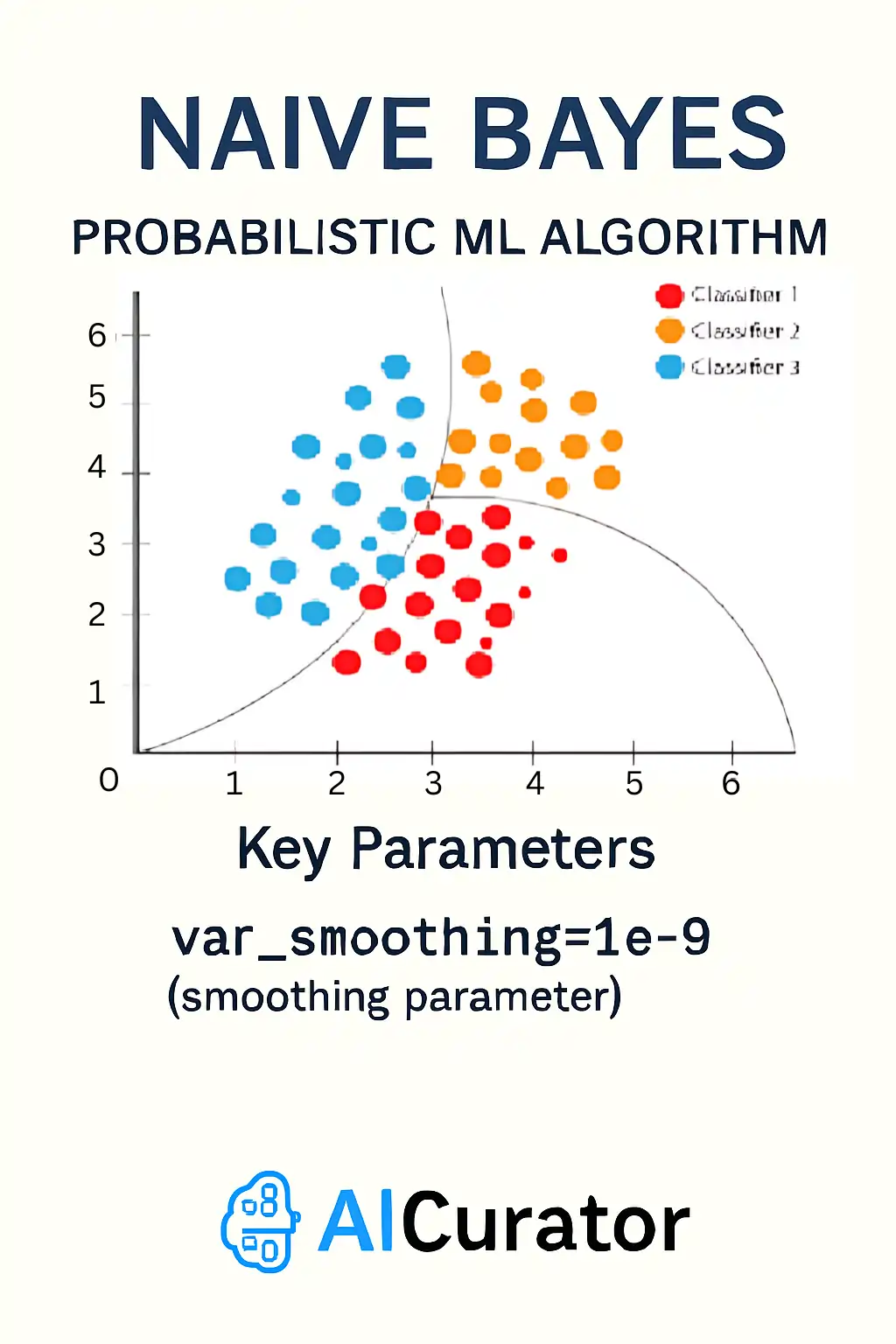
Naive Bayes applies Bayes’ rule under the assumption that input features act independently once the class is known. It simply counts how often words, pixels, or other tokens appear in each class, then multiplies those probabilities to score new examples.
Training and prediction are lightning fast, making it a staple for email spam blocking and quick sentiment checks. Smoothing combats zero counts, and independence limits accuracy when features are strongly related.
Key Parameters
python
from sklearn.naive_bayes import GaussianNB
model = GaussianNB(var_smoothing=1e-9)Applications: Sentiment analysis, document classification, spam detection
Pros
Cons
6. Artificial Neural Networks: Advanced AI Algorithms
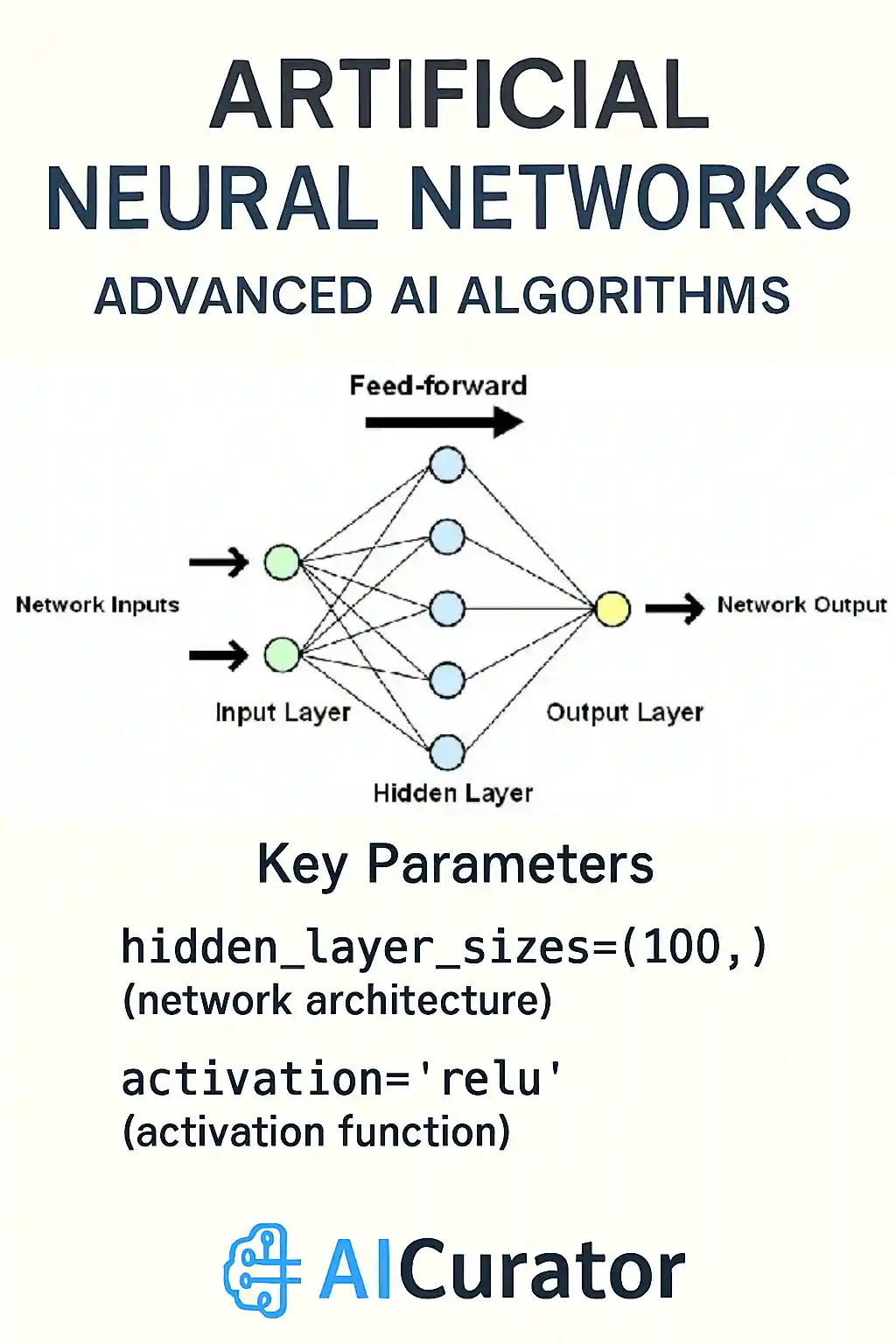
Neural Networks stack layers of tiny processing units that pass signals forward, adjust weights backward, and gradually learn complex rules. They top many lists of Machine Learning Algorithms because the same framework scales from recognizing handwritten digits to translating speech.
A hidden layer picks up subtle patterns, activation functions add non-linearity, and optimizers such as Adam speed up learning. Success often hinges on plenty of data, careful regularization, and thoughtful architecture choices.
Key Parameters
python
from sklearn.neural_network import MLPClassifie
model = MLPClassifier(hidden_layer_sizes=(100,), activation='relu')Applications: Voice recognition, image processing, fraud detection
Pros
Cons
7. Self-Organizing Maps: Unsupervised Learning Algorithm
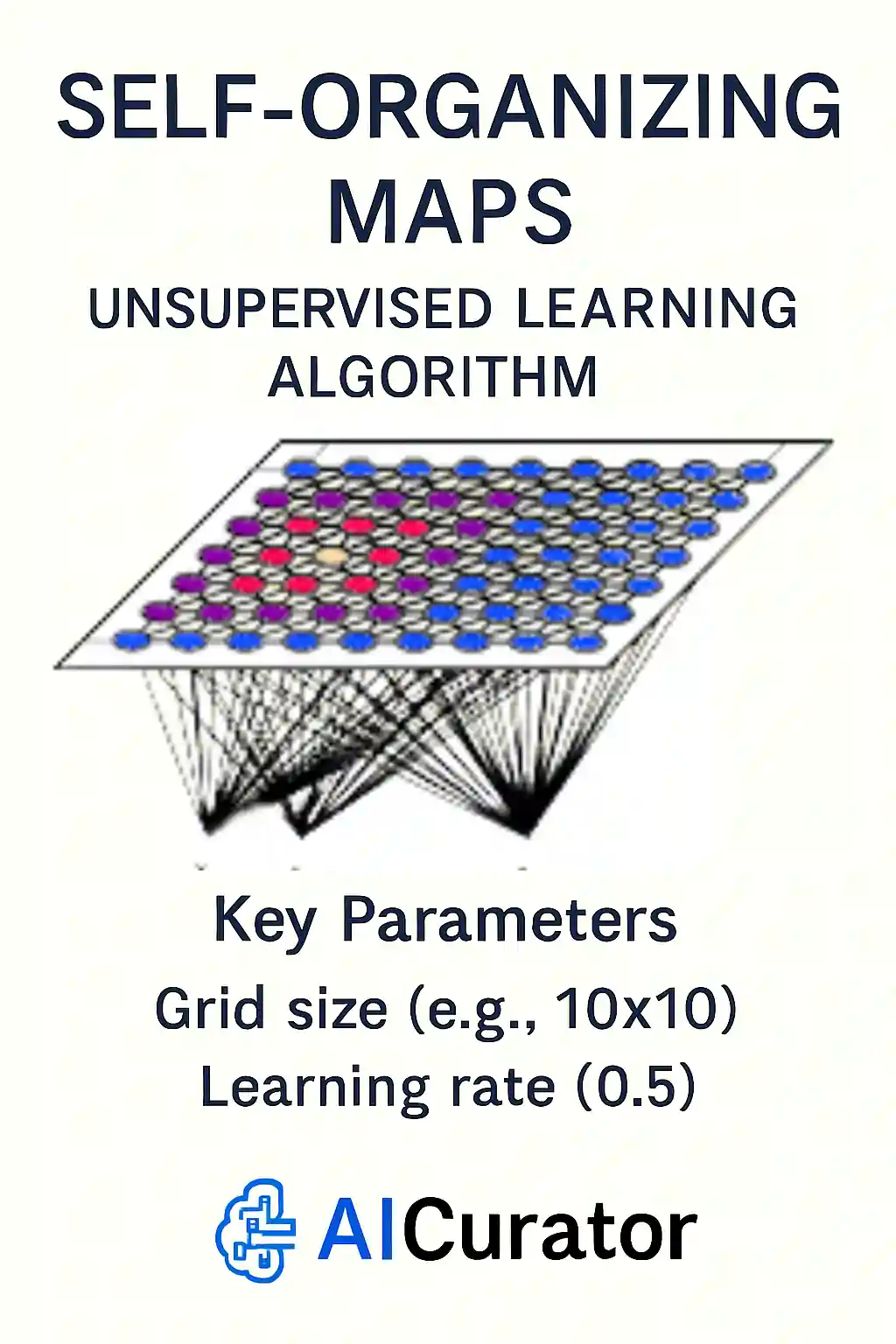
A Self-Organizing Map places data points onto a two-dimensional grid, nudging nearby neurons together so similar items land close by. The result is an intuitive picture of clusters, gradients, or outliers, useful for exploratory work and pattern discovery.
Because training relies on simple distance calculations and neighborhood updates, SOMs handle dozens of features with modest computing power. Map size, neighborhood shape, and learning rate are the main dials for tuning performance.
Key Parameters
python
from minisom import MiniSom
som = MiniSom(10, 10, input_len=4, sigma=1.0, learning_rate=0.5)Applications: Market segmentation, anomaly detection, data visualization
Pros
Cons
8. Dimensionality Reduction: Essential Data Science Algorithms

PCA is an unsupervised machine learning technique that rotates the data to find directions holding the most variation, then lets you drop the weaker axes to shrink dimensionality. By keeping only the leading components, you trim noise and speed up later steps while still preserving the big picture.
It’s handy for visualizing high-dimensional sets and easing multicollinearity, though the transformed features can feel abstract compared with the originals.
Key Parameters
python
from sklearn.decomposition import PCA
pca = PCA(n_components=2)Applications: Feature selection, data compression, visualization
Pros
Cons
9. XGBoost: Advanced Ensemble Algorithm
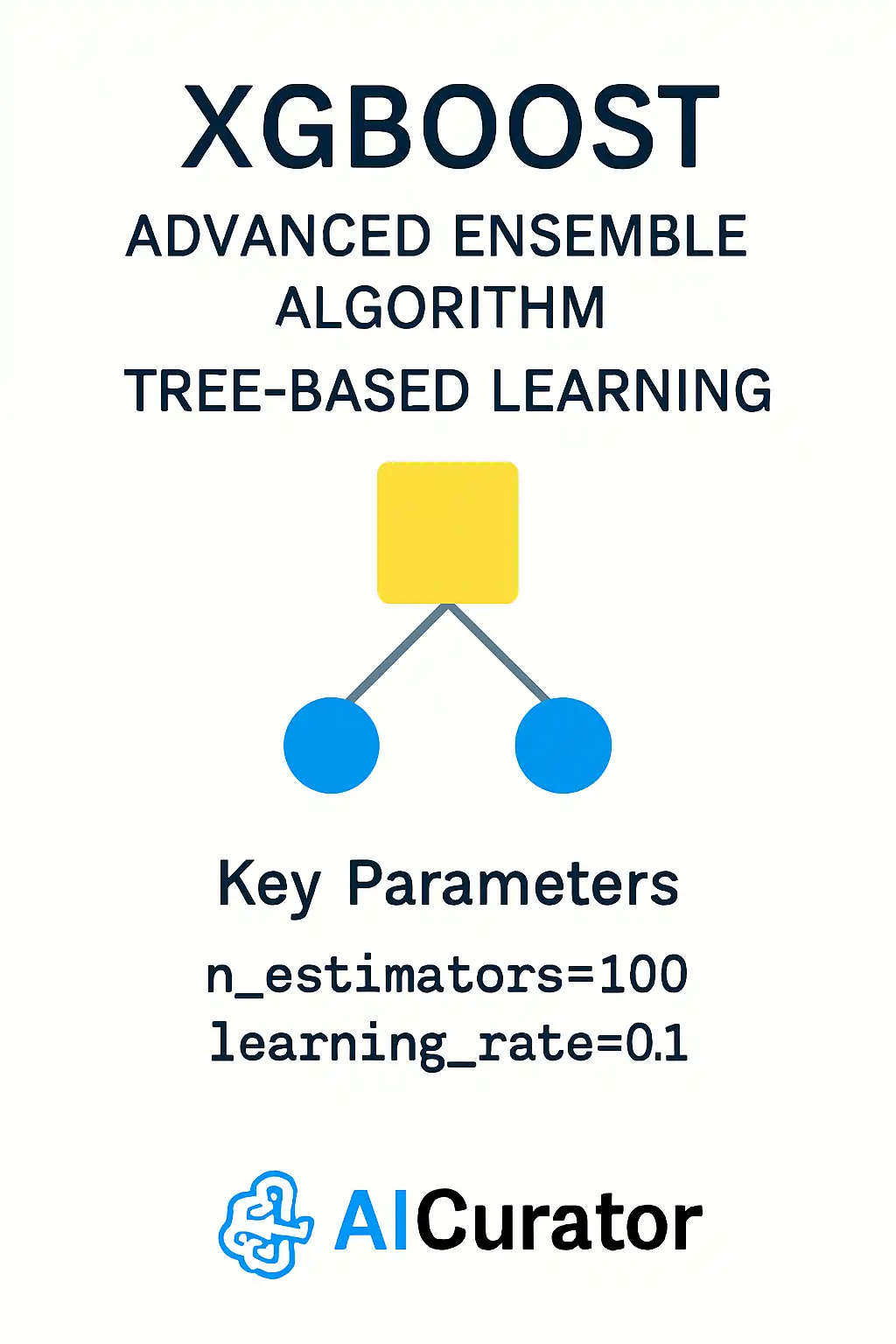
XGBoost builds many small trees one after another, each one fixing the mistakes of the last by following gradient signals. Regularization, column sampling, and smart handling of missing values keep overfitting and run-time in check.
As a result, this machine learning model often ranks near the top in data-science contests. Parallel processing and out-of-core options let it chew through big tables quickly, but its many settings call for systematic tuning.
Key Parameters
python
from xgboost import XGBClassifier
model = XGBClassifier(n_estimators=100, learning_rate=0.1)Applications: Kaggle competitions, structured data prediction, ranking systems
Pros
Cons
10. LightGBM: Efficient Gradient Boosting Algorithm
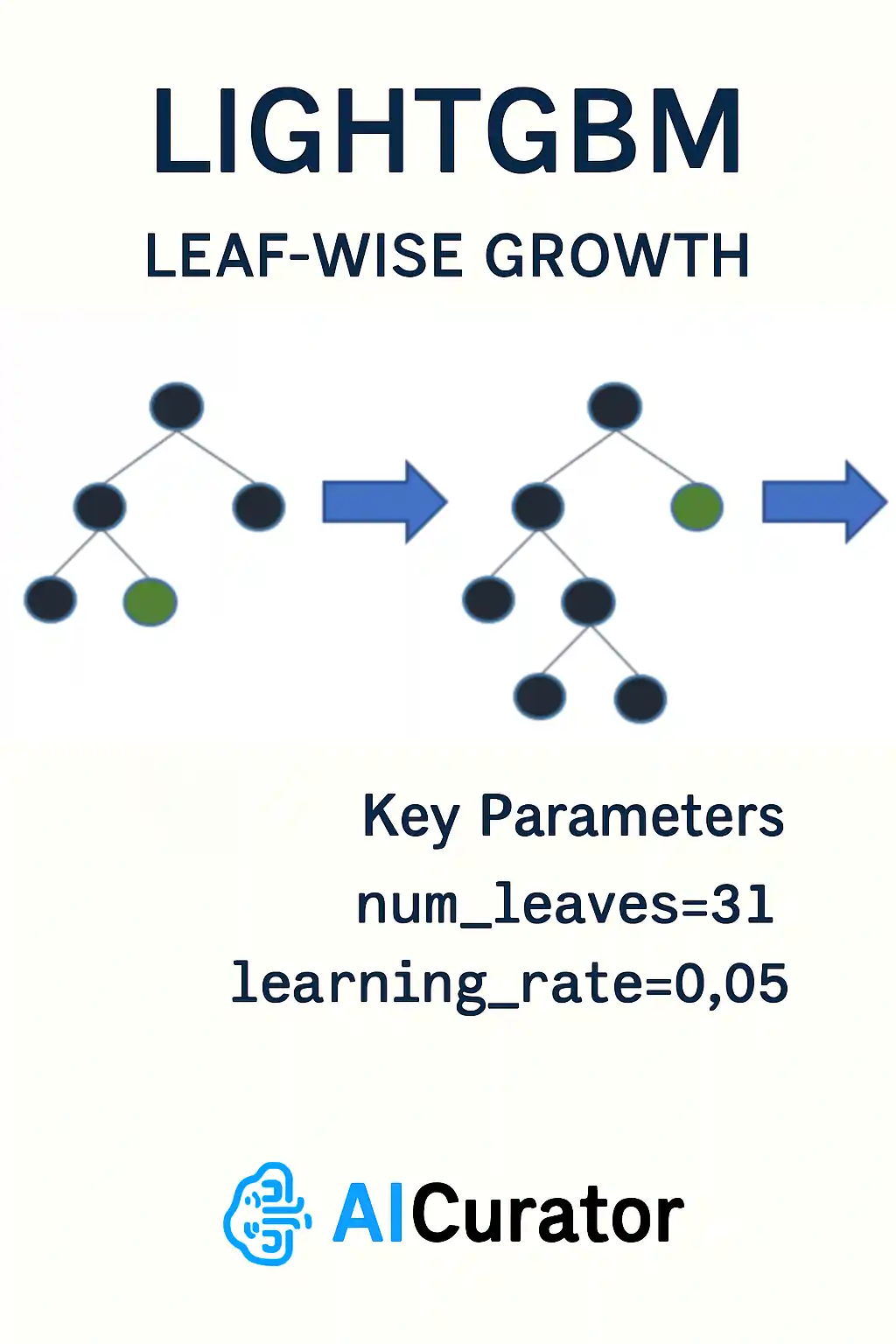
LightGBM speeds up gradient boosting by grouping continuous values into bins, then growing each tree leaf-wise so splits focus on the most promising regions first. Exclusive feature bundling and automatic handling of categories cut memory use, letting it work smoothly on wide, sparse data.
GPU support and distributed training add more scale. Because the trees can grow deep fast, care is needed with max-depth and regularization to keep predictions general.
Key Parameters
python
import lightgbm as lgb
model = lgb.LGBMClassifier(num_leaves=31, learning_rate=0.05)Applications: Real-time recommendation systems, large-scale classification, time-series forecasting
Pros
Cons
Mastering Machine Learning Algorithms for 2026 Success
In 2026, mastering both traditional and modern machine learning algorithms is key to building effective AI systems.
Start with core supervised learning models and practice on real datasets to refine your predictive modeling skills.
Stay current with evolving ML techniques through platforms like Hugging Face and research communities. These top 10 Machine Learning algorithms form the backbone of success in today’s fast-moving, digital-first environment.









{kind=link}