





Struggling to find reliable machine learning interview material for 2026?
This guide is structured to help you navigate the most common questions hiring managers ask for data science and AI roles. We cover fundamental concepts from supervised learning and gradient descent to advanced topics like GANs and XGBoost.
The answers are direct, concise, and designed to provide the clarity needed to build confidence and demonstrate your expertise during technical assessments, helping you secure a position in the field.
ML Interview Questions: Key Takeaways
Preparation Strategies for Machine Learning Job Interviews
Candidates aiming for roles in data science often benefit from structured approaches to tackle machine learning questions. Focus on practicing algorithms through coding platforms to build familiarity with concepts like decision trees and support vector machines.
Review datasets from public repositories to simulate real scenarios, ensuring skills in data preprocessing and model tuning align with common interview formats. Incorporate mock sessions that emphasize explaining solutions clearly, as interviewers assess both technical depth and communication abilities.
This method helps in mastering pattern recognition and optimization algorithms, key elements in AI-related assessments.
🧠 Crack Your ML Interview with These 30 Killer Questions!

1. What is Machine Learning?
Machine learning is a subset of artificial intelligence where algorithms learn patterns from data to make predictions or decisions without explicit programming. It enables systems to improve performance over time through experience, powering applications like recommendation engines and image recognition.
2. What are the Categories of Machine Learning?
Machine learning categories include supervised learning (labeled data for predictions), unsupervised learning (finding patterns in unlabeled data), semi-supervised learning (mix of both), and reinforcement learning (learning via rewards and penalties). These form the backbone of AI model development.
3. What is Overfitting?
Overfitting occurs when a model learns noise and details from training data too well, performing poorly on new data. It results in high accuracy on training sets but low generalization. For example, a complex polynomial fitting every point in a noisy dataset fails on unseen samples.
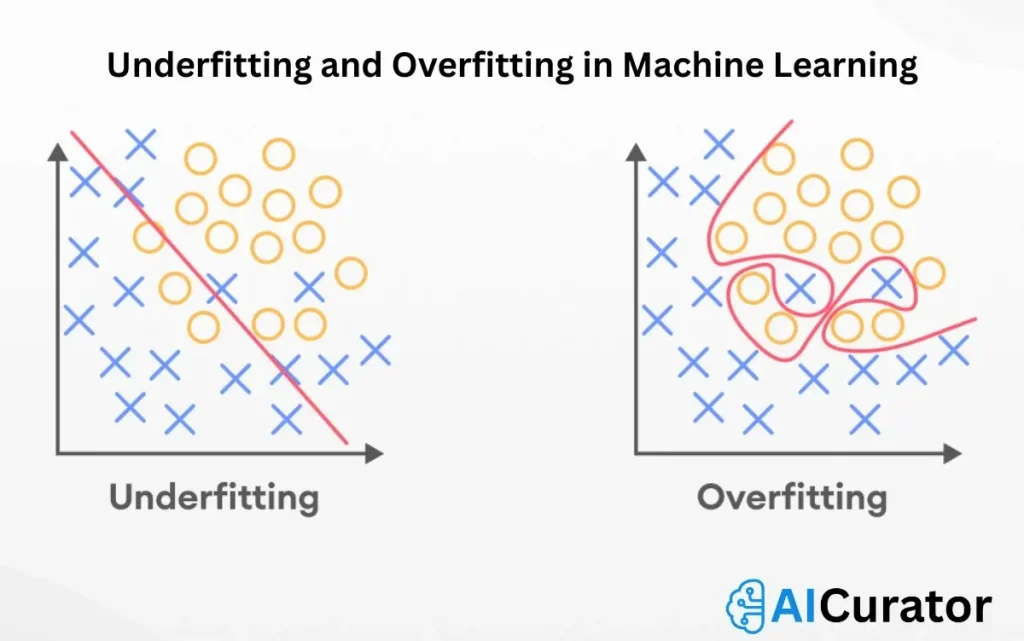
4. What is Underfitting?
Underfitting happens when a model is too simple to capture underlying patterns in data, leading to poor performance on both training and test sets. It often stems from insufficient features or inadequate training, like using a linear model for nonlinear relationships.
5. What is the distinction between Classification and Regression?
Classification predicts discrete categories (e.g., spam or not spam), while regression forecasts continuous values (e.g., house prices). Classification uses metrics like accuracy; regression employs MSE. Example: Email filtering is classification; stock price prediction is regression.
6. What is Bias and Variance?
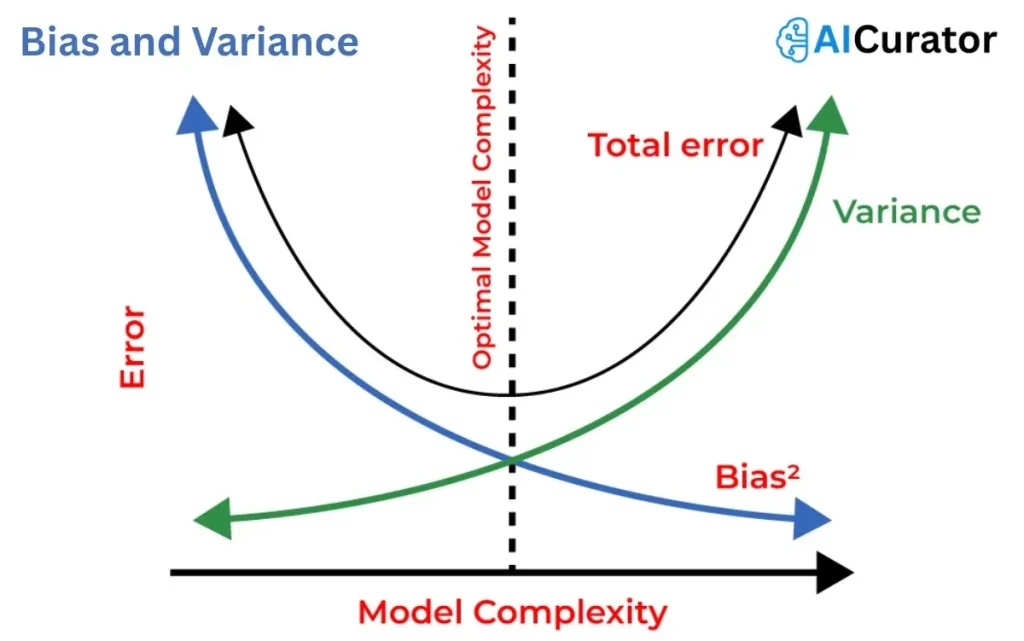
Bias is the error from simplistic assumptions, causing underfitting. Variance is error from sensitivity to training data fluctuations, leading to overfitting. High bias models miss patterns; high variance ones overreact to noise.
7. What is a Feature in Machine Learning?
A feature is an individual measurable property or characteristic of data used as input for models. It represents variables like age or pixel values in images, crucial for pattern recognition and prediction accuracy in algorithms.
8. How does Feature Engineering Work?
Feature engineering involves selecting, transforming, and creating new features from raw data to improve model performance. It includes scaling, encoding categoricals, and handling missing values, turning complex data into model-ready inputs for better accuracy.
9. Explain the Difference between Supervised and Unsupervised Learning.
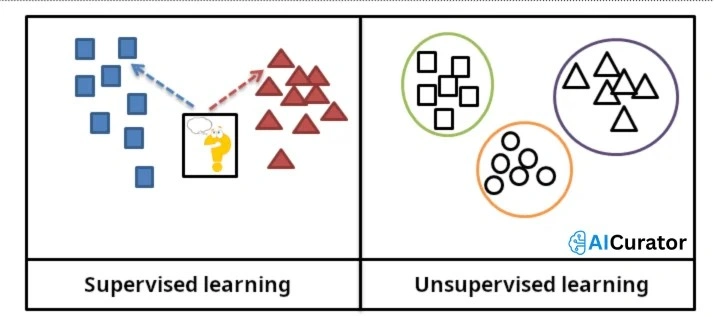
Supervised learning uses labeled data to train models for predictions, like classification tasks. Unsupervised learning analyzes unlabeled data to find hidden structures, such as clustering. Supervised requires guidance; unsupervised discovers patterns independently.
10. What is Gradient Descent and How Does it Work?
Gradient descent is an optimization algorithm that minimizes a model's loss function by iteratively adjusting parameters in the direction of steepest descent. It calculates gradients and updates weights using a learning rate, converging to optimal values for training.
11. Describe the Curse of Dimensionality.
The curse of dimensionality refers to challenges when data has too many features, leading to sparsity, increased computation, and overfitting. As dimensions grow, distances become less meaningful, degrading model performance in high-dimensional spaces.
12. What is Ensemble Learning?
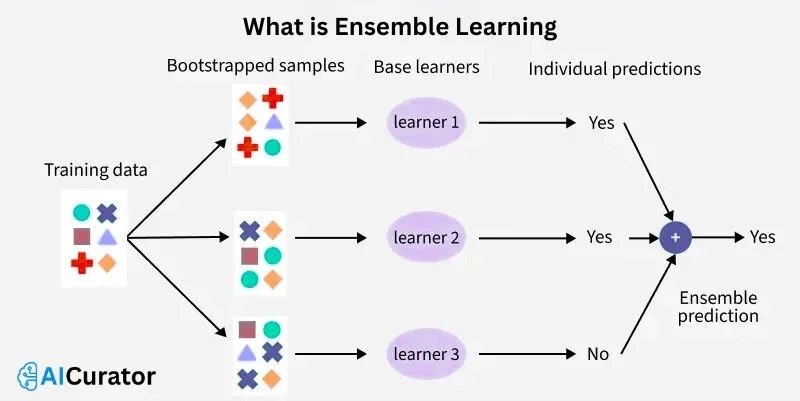
Ensemble learning combines multiple models to improve accuracy and robustness, reducing errors from individual learners. Techniques include bagging and boosting. Example: Random forests aggregate decision trees for better predictions in classification tasks.
13. How does a Convolutional Neural Network (CNN) differ from a Standard Neural Network?
CNNs specialize in grid-like data like images, using convolutional layers for feature extraction and pooling for dimensionality reduction, unlike standard neural networks that process flat inputs without spatial hierarchies.
14. What is Reinforcement Learning?
Reinforcement learning trains agents to make sequential decisions by rewarding desired actions and penalizing others in an environment. It focuses on long-term goals, like training a robot to navigate mazes through trial and error.
15. Explain the concept of Hyperparameters in Machine Learning Models.
Hyperparameters are settings configured before training, like learning rate or number of trees, that control the model's learning process. They aren't learned from data and require tuning via methods like grid search for optimal performance.
16. What is the Role of Activation Functions in Neural Networks?
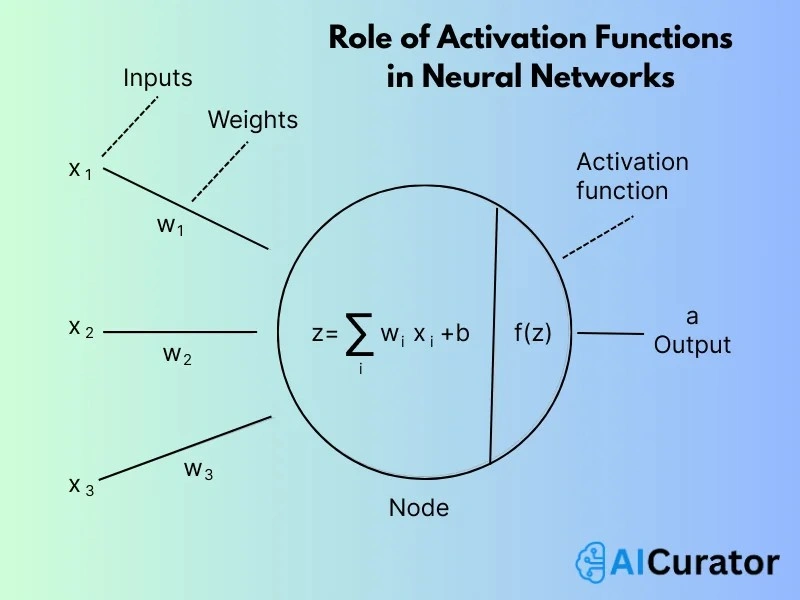
Activation functions introduce nonlinearity, enabling neural networks to model complex patterns. They decide neuron outputs, preventing linear transformations. Common ones include ReLU for speed and sigmoid for binary outputs.
17. How do you handle Imbalanced Datasets?
Handle imbalanced datasets with techniques like oversampling minority classes (e.g., SMOTE), undersampling majority classes, using class weights, or ensemble methods. These ensure models don't bias toward dominant classes in classification tasks.
18. What is k-means Clustering and its Limitations?
K-means clustering partitions data into k groups by minimizing intra-cluster variance, assigning points to nearest centroids iteratively. Limitations include sensitivity to initial centroids, assumption of spherical clusters, and need to specify k in advance.
19. Describe the Bias-Variance Tradeoff.
The bias-variance tradeoff balances model complexity: high bias causes underfitting by oversimplifying, while high variance leads to overfitting by capturing noise. Optimal models minimize total error for better generalization on unseen data.
20. What is a Kernel in SVM?
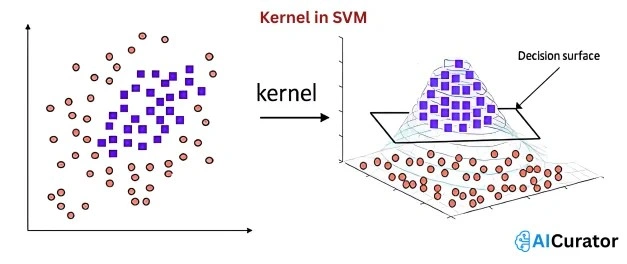
A kernel in SVM transforms data into higher-dimensional space for nonlinear separation, enabling complex decision boundaries. Common kernels include linear, polynomial, and RBF, allowing SVMs to handle non‑linearly separable data effectively.
21. Explain Batch Normalization.
Batch normalization normalizes layer inputs in neural networks, reducing internal covariate shift for faster training and higher accuracy. It scales activations per mini-batch, stabilizing gradients and allowing higher learning rates.
22. What is the Vanishing Gradient Problem?
The vanishing gradient problem occurs in deep networks when gradients become extremely small during backpropagation, halting weight updates and slowing learning. It affects sigmoid activations in long sequences, impeding training of deep layers.
23. How does XGBoost differ from Random Forests?
XGBoost is a boosted tree algorithm optimizing for speed and performance with regularization and parallel processing, while random forests use bagging for variance reduction. XGBoost handles missing data better and often outperforms on structured data.
24. What is One-hot Encoding?
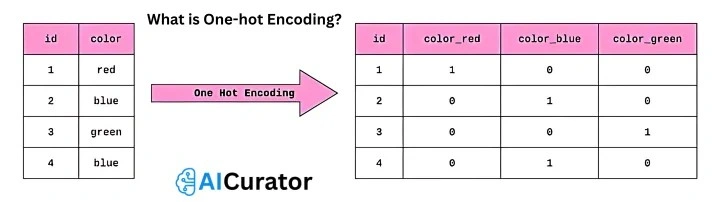
One-hot encoding converts categorical variables into binary vectors, creating a column per category with 1 for presence and 0 otherwise. It prevents ordinal assumptions in models like neural networks. Example: Encoding colors red, blue, green as separate binary vectors.
25. Describe the process of Model Evaluation Metrics for Regression Tasks.
Evaluate regression models using metrics like Mean Squared Error (MSE) for average squared differences, Root Mean Squared Error (RMSE) for error magnitude, Mean Absolute Error (MAE) for average absolute differences, and R‑squared for variance explained.
26. What is Deep Learning?
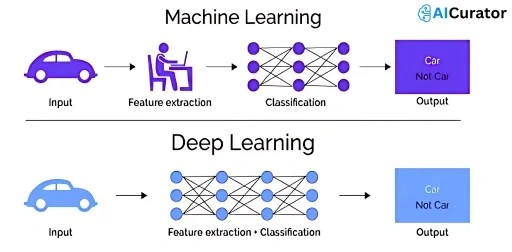
Deep learning is a machine learning subset using multi-layered neural networks to model complex patterns from large datasets. It excels in tasks like image and speech recognition, automatically extracting features without manual engineering.
27. Explain the concept of Learning Rate in Optimization.
Learning rate determines step size in parameter updates during optimization like gradient descent. Too high causes divergence; too low slows convergence. Adaptive methods like Adam adjust it dynamically for efficient training.
28. What is Autoencoder and its Applications?
An autoencoder is a neural network that learns efficient data representations by encoding inputs to a compressed form and decoding back. Applications include dimensionality reduction, anomaly detection, and image denoising, like removing noise from photos.
29. How do you prevent Overfitting in Neural Networks?
Prevent overfitting with techniques like dropout (randomly disabling neurons), early stopping (halting training when validation performance degrades), data augmentation, regularization (L1/L2), and cross‑validation to ensure generalization.
30. What is Generative Adversarial Network (GAN)?
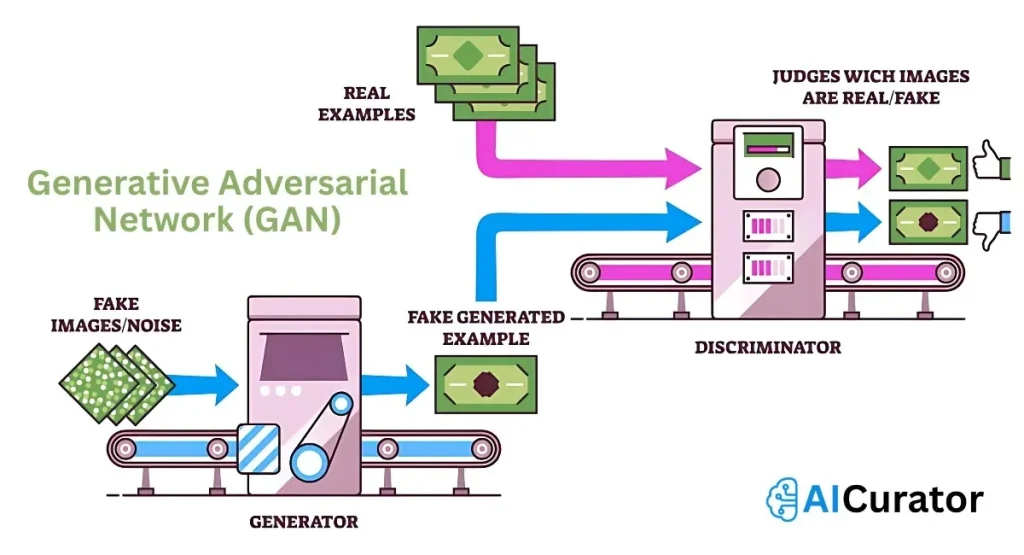
A GAN consists of a generator creating fake data and a discriminator distinguishing real from fake, trained adversarially to improve both. It generates realistic images or data, with applications in art creation and data augmentation.
Seal Your Path to Machine Learning Mastery

Having reviewed these key questions, you are now better equipped for the challenges of a modern machine learning interview. Success is not just about knowing definitions but explaining complex topics like the bias-variance tradeoff and neural network functions with clarity.
Use this guide as a checklist to identify areas for deeper study and practice articulating your responses. Continue refining your understanding of these core principles to confidently approach your next career opportunity in the AI and data science sector.









{kind=link}